



























Data Quality in Snowflake
16 December 2023
Amazon AWS vs. Alibaba Cloud
16 December 2023
Tags
Published by
BluePi
Data-Driven Business Transformation
Data Engineering in Snowflake
Data engineering is the process of creating systems that make it possible to collect and use data. The majority of the time, this data is utilized to support further analysis and data science, which often includes machine learning among other things. Data Pipelines are needed for this.
A series of data processing operations is called a data pipeline. If it hasn’t already been added to the data platform, the data is ingested at the beginning of the pipeline. The next series of actions each result in an output that is used as the initial step’s input. Until the pipeline is finished, this keeps happening. Sometimes separate actions can be carried out in parallel. Data-driven digital transformation requires robust data engineering to achieve successful outcomes. A well-designed data engineering process ensures that the right data is collected, processed, and analyzed in a timely and accurate manner.
Most businesses deal with enormous amounts of data. You require a single view of the complete data collection in order to analyze all of that data. It is necessary to aggregate that data in ways that make sense for in-depth analysis when it is spread across several systems and services. Data flow itself can be unreliable since there are several opportunities for corruption or blockages to occur as it is being transferred from one system to another. The difficulties progressively widen in extent and severity as the breadth and scope of the role data play expands.
Data pipelines are essential for this reason. They offer a seamless, automatic data flow from one stage to the next by eliminating the majority of manual procedures from the process. They are necessary for real-time analytics because they facilitate quicker, data-driven decision-making.
Bringing all of your data silos together into a single source of truth assures consistent data quality and makes it possible to conduct speedy data analyses for business insights.
Effective data pipelines can make the difference between an architecture that actually adds value to the business and one that just becomes a nuisance for data engineers. To meet business expectations, data engineers must be able to gather, transform, and transmit data to various business lines while staying abreast of technological advancements. Traditional legacy structures, however, present difficulties at every turn.
First, data is produced at various speeds and comes in all shapes and sizes. With a legacy design, data frequently ends up in various databases, data lakes, data marts, the cloud, and both on- and off-premises servers.
In addition, performance declines when resources are scarce. The prioritization of analytical workloads reduces the performance of data pipelines. With complicated pipelines and architecture, this causes a bottleneck for both data integration and consumption downstream. Instead of focusing on providing data, data engineers are primarily responsible for configuring and managing infrastructure. Data pipelines are very time-consuming to create and manage since legacy and open-source systems frequently call for specialized knowledge and unique coding. As a result, IT Teams are burdened with an incredible amount of technical debt and are forced to react to business needs more quickly. Additionally, the data available to analysts and commercial decision-makers is insufficient and erroneous.
Snowflake delivers the performance and scalability modern enterprises require to support thousands of concurrent users without resource contention by streamlining data pipelines and modernizing data integration workloads. It also offers a single platform for adjusting all structured and semi-structured data as well as secure and governed access.
Snowflake streamlines data engineering while also combining complex analytics, data lakes, and data-sharing tasks into a simple, low-maintenance service that is compatible with all three major clouds. Both structured and semi-structured data may be easily consumed through batch or streaming processes with Snowflake and its partners, making it directly available to your users. Pipelines can operate on optimal dedicated resources without manual configuration and scale up or down automatically as necessary, which improves pipeline performance and reduces costs. Snowflake also uses SQL to speed up pipeline construction, decreasing complexity by eliminating the need to maintain extra clusters and offering built-in data input and pipeline management features.
ETL and ELT
Data integration is the first stage in every data pipeline. Both the ETL and ELT acronyms refer to procedures for preparing data for use in data analytics, business intelligence, and data science by cleansing, enriching, and transforming information from a number of sources before integrating it.
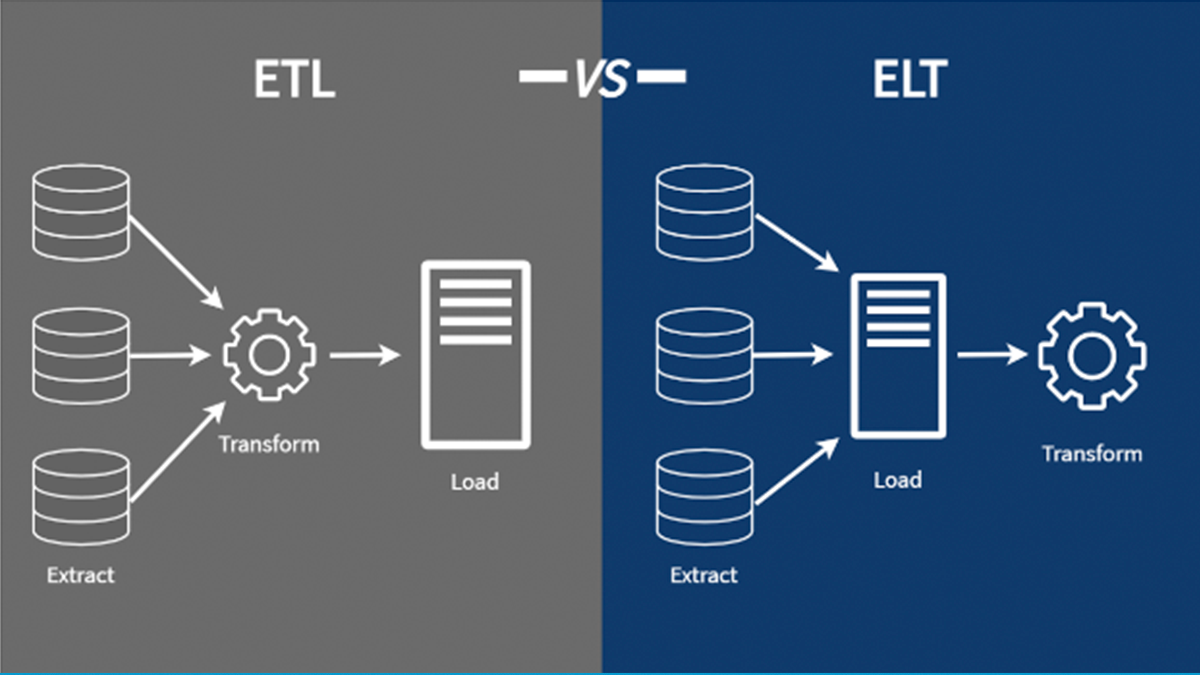
The words in the acronym stand for Extract, Transform, and Load.
- The term “extract” describes the procedure of obtaining data from a source, such as an XML file, a cloud platform, or a SQL or NoSQL database.
- The term “transform” describes the procedure of changing a data set’s format or structure to conform to the requirements of the destination system.
Load refers to the Input of a data set into a target system. - The timing of data transformation is what separates ETL and ELT.
The question is, which is better?
There is no solitary solution to this. There is a place for each process. Small data sets requiring intricate transformations are a good fit for the ETL process. When timeliness is crucial and larger, unstructured, and structured data sets are involved, the ELT procedure is more suitable.
The transition from ETL to ELT has been going on for a while. Since a data warehouse had historically served as the destination repository, ETL pipelines have long been the industry standard for data integration. However, ETL is more time-consuming for ad hoc analysis because the entire procedure must be redone for each use case. It also requires expensive hardware and ongoing IT support. Furthermore, initiatives involving real-time analytics or machine learning cannot be supported by the ETL procedure. These business requirements, along with current agile development methodologies and cloud architectures, have hastened the transition from ETL to ELT.
Transformations in Snowflake
ETL and ELT are supported by Snowflake, which also works with a variety of data integration tools. After the data has been ingested into a Snowflake landing table, a number of tools are available to clean, enhance, and alter the data. These tools are shown in the picture below.
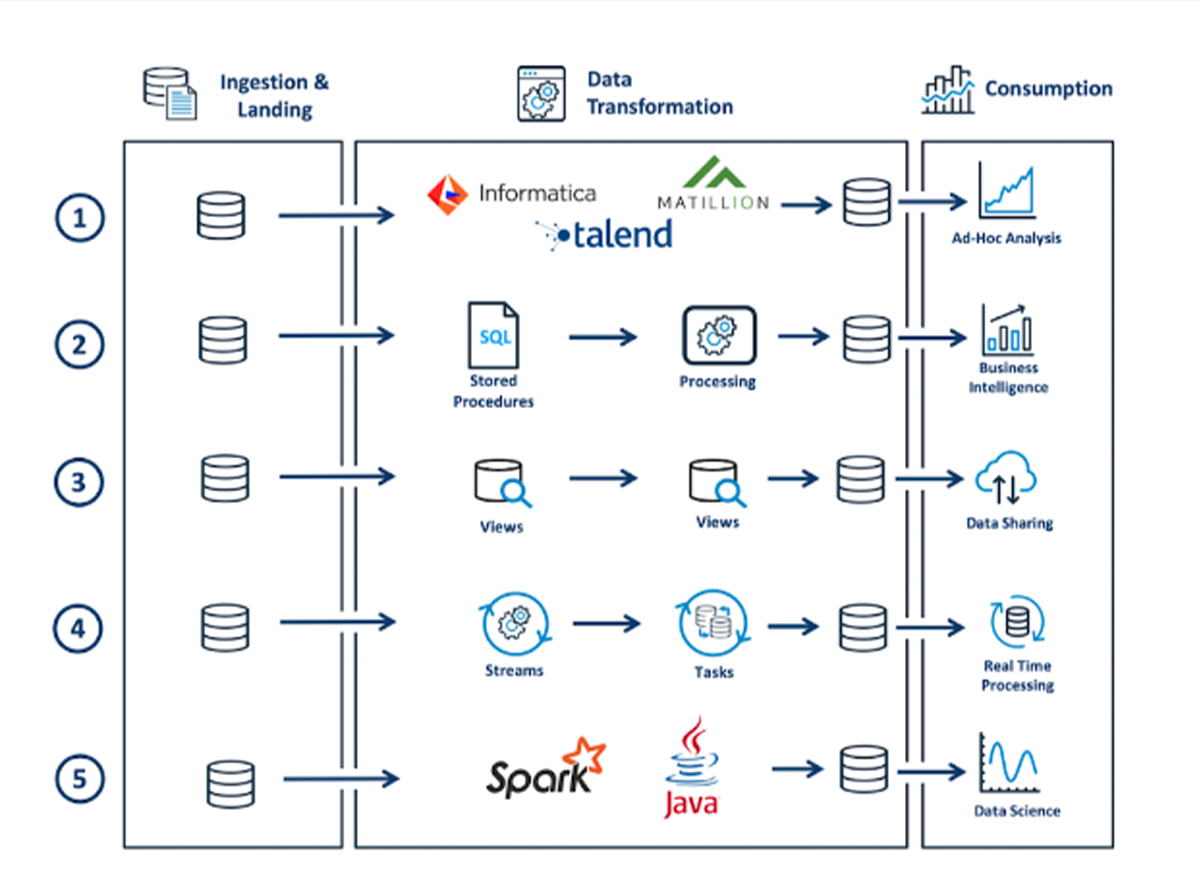
The possibilities for data transformation include
- Using ELT Tools: This frequently has the benefit of making use of the data engineering team’s already-existing skill set, and Snowflake supports a variety of data integration solutions.
- Using Stored Procedures: The procedural language Snowflake Scripting is another feature of Snowflake in addition to the API. This contains support for dynamic SQL that is similar to Oracle’s PL/SQL as well as loops and cursors.
- Incremental Views: A real-time transformation pipeline is constructed using a number of views that are stacked upon one another. Breaking down complicated pipelines into smaller phases and writing interim results to transient tables is a good idea since it makes them simpler to test and debug and, in some situations, can result in considerable performance gains.
- Streams & Tasks: A highly effective yet straightforward method of establishing simple change data capture (CDC) within Snowflake is through the use of Snowflake Streams. Combining Streams with Snowflake Tasks on data that has been obtained for processing in close to real-time is a smart practice. In essence, the Task offers a schedule to regularly change the newly received data while the Stream maintains a pointer in the data to record the data already processed. The latest release of the Serverless Computing option significantly simplifies the operation and ensures that Snowflake automatically controls the compute resources, scaling up or out as needed. Previously, it was necessary to assign a suitable-sized virtual warehouse to carry out the task.
- Spark and Java on Snowflake: Data engineers and data scientists who previously loaded data into a Databricks Cluster to run SparkSQL jobs can now develop using Visual Studio, SBT, Scala, and Jupyter notebooks with Spark DataFrames automatically translated and executed as Snowflake SQL thanks to the Snowpark API, which was recently released. This gives you strong alternatives to transform data in Snowflake using your preferred development environment without the extra expense and complexity of supporting external clusters when combined with the ability to run UDFs.
The aforementioned data transformation patterns illustrate the most typical approaches, however, each Snowflake component can be easily mixed as necessary. - Snowpark
For querying and processing data in a data pipeline, the Snowpark library offers an easy-to-use API. By using this library, you can create programs that use Snowflake to process data without having to transfer the data to the computer running your program’s code.
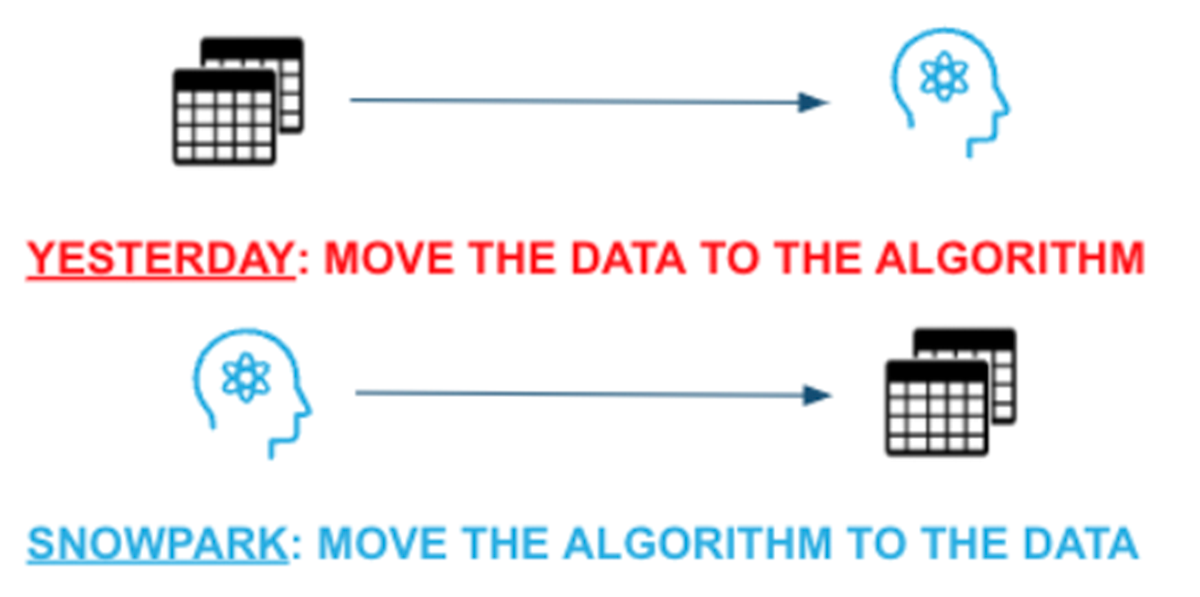
- It gives programmers the ability to create code in Python, Java, and Scala that will enable businesses to transfer data by interacting with an API.
- In contrast to the past, when Code Development and Deployment required separate infrastructure and upkeep to achieve this, Snowpark offers the opportunity for designing Applications that link with Snowflake natively.
- By directly connecting to Snowflake’s Virtual Data Warehouse, Snowpark eliminates the lengthy startup times for distributed resources where systems need clusters of nodes to perform specific activities. With a focus on data-driven digital transformation, Bluepi is recognized as one of the best snowflake service providers in India, providing a comprehensive range of snowflake services and solutions. As an organization with Snowpro-certified consultants, Bluepi offers data lake and data warehousing services in Snowflake, helping businesses to manage their data efficiently and effectively. The company provides advanced data analytics and engineering services, allowing businesses to harness the power of their data to drive digital transformation.
About the Author

Published by
Ayushi Kaushik
Associate Technical Lead
An Associate Technical Lead is a key player in our innovation journey, guiding technical teams with expertise and vision. They bridge the gap between strategic goals and technical implementation, ensuring projects are executed seamlessly. As a hands-on leader, they mentor and inspire, fostering a culture of collaboration and excellence







{kind=link}
{kind=link}