


























What is a data lake and why does your enterprise need it?
1 March 2023
Security in Snowflake
22 March 2023
Tags
Published by
BluePi
Data-Driven Business Transformation
High Availability and Disaster Recovery in Snowflake
High Availability
Let’s first define high availability to better grasp the high availability features that Snowflake offers to offer.
The term “high availability” (HA) describes a system’s capacity to function continuously without error for a predetermined amount of time. HA works to make sure a system satisfies a predetermined standard of operational performance.
Several factors make high availability crucial.
- Protection from downtime
- Protects you from losing revenue
- Makes maintenance simpler
- Most flexibility
- Increases your adaptability and resilience
A highly available data platform in the cloud, Snowflake was created with a 99.9% or higher availability service level across all editions. To help customers ensure that their data and data platform are always available while relieving them of some infrastructure management duties, it has integrated comprehensive fault tolerance and resiliency into its product.
One could now question how Snowflake manages to reach such high availability. So, the Snowflake architecture is made up of three layers, each of which is independent of the others and spread across many data centers to ensure failure tolerance.
Let’s now get more specific and talk about how highly available each of these levels is.
Centralized Storage Layer:
All customer data is stored in an encrypted format in Snowflake’s database storage layer. All persistent data is kept by Snowflake in the cloud object storage of your preferred cloud provider. Transactions are only finalized after all updated data has been stored in the cloud. In turn, cloud storage replicates the data across numerous devices and at least three availability zones synchronously and automatically. Snowflake is built on the blob stores of the cloud providers, all of which boast durability ratings of at least 11 9s.
Multi-Cluster Compute:
The architecture of Snowflake also makes sure that queries succeed despite a variety of errors. The virtual warehouses process the tasks involved in query execution. Within a virtual warehouse, if a single compute instance fails, Snowflake automatically replaces that instance, allowing the query to run uninterruptedly. The data in virtual warehouses is not kept indefinitely. Instead, they use data caching to speed up queries. Since the persistent copy of the data is stored in the cloud object stores, the loss of any number of nodes within a virtual warehouse, including the loss of a complete virtual warehouse, does not result in data loss.
Cloud Services Layer:
The cloud services layer is the top layer and is where Snowflake processes requests from connected clients and offers services like security, virtual warehouse management, query optimization, and metadata management. Additionally, this layer is built for resilience, making the Snowflake Data Cloud fault tolerant across a wide range of failure situations. The cloud services layer accounts for the cloud service providers’ physical availability zones. All updates are synchronously committed to numerous instances in various availability zones because it is spread across different virtual compute instances. In the event that one or more of the instances supporting it fail, or even the loss of up to two data centers, the metadata storage system can continue to operate without interruption and without data loss.
One fantastic thing, though, is that Snowflake allows for uninterrupted functioning both during failures and during software updates. This means that, unlike other infrastructure-hosted systems that require downtime for conventional database maintenance tasks, Snowflake customers do not have to invest time or effort in maintaining it.
Customers might eventually need Snowflake to provide better than 99.9% availability for their applications. The following extra features offered by Snowflake can help customers achieve higher availability:
Replication of a database
- If a cloud area outage hits Snowflake, for instance, customers can copy their data to another Snowflake account in a different region. Additionally, customers can replicate their data across several cloud service providers like GCP, Microsoft Azure, and AWS. Only read-only access is given to duplicated databases.
- This requires Snowflake Enterprise Edition or a higher version.
- For instance, this method enables you to direct Snowflake clients to read-only copies of crucial databases first for minimal downtime when an outage in a region causes full or partial loss of Snowflake availability.
Failover/Failback
Failover is a backup operational mode in which a secondary component takes over a system component’s functions when the primary component is rendered unavailable due to failure or planned downtime. Mission-critical systems must include failover.
In snowflake,
- You can start a failover if a database needs read-write replication by designating a secondary replica database in an available area to serve as the primary database. The database is made writeable when it is promoted. The previous primary database is changed into a secondary, read-only database at the same time.
- This requires Snowflake Business Critical Edition or a higher version.
- For instance, we can designate replicas of crucial databases in another area to act as the primary databases during outages, enabling writing to these databases. You can use your ETL processes to organize write and reconcile data after the databases are writable. The databases in the Snowflake account where the outage occurred can now be promoted to once again act as the primary databases once the outage has been fixed.
Client redirect
- When a failover occurs during an outage, client redirect enables clients to be automatically routed within seconds.
- Every replica uses the same URL for redirection.
Let’s talk about disaster recovery.
Disaster Recovery
Customer expectations have risen in today’s digital economy. There is very limited tolerance for service-level gaps and transaction delays, so even a brief period of digital outage can result in losses in productivity, sales, and client loyalty. Every firm should have a solid disaster recovery (DR) plan because of this. A disaster recovery plan outlines how and when you’ll recover from an event that unexpectedly makes important apps and data inaccessible. As a result, it gets you ready to return online swiftly, minimizing harm to your company. Snowflake is well-known for being quite accessible. The table that follows demonstrates how it avoids data loss in a variety of failure scenarios.
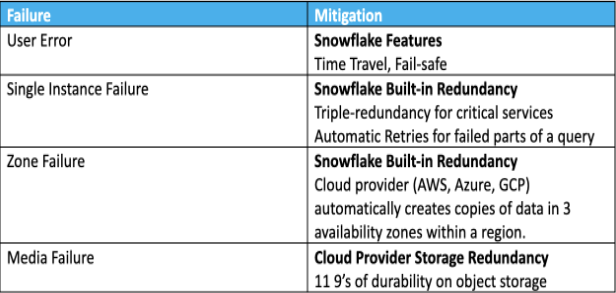
Currently, Snowflake has two capabilities that are intended exclusively for user error-related disaster recovery. These offer basic hardware or user error correction.
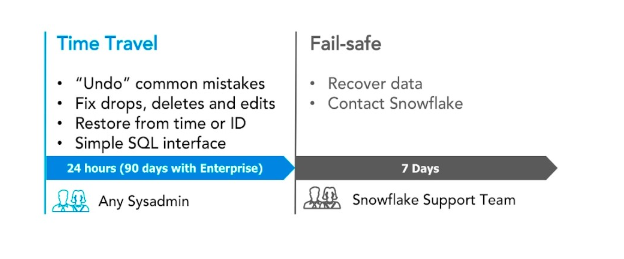
Time Travel
As the name would suggest, there is a connection to traveling back in time. Thanks to Snowflake Time Travel, historical data—that is, data that has been changed or removed—can be accessed at any time throughout a predetermined duration. It works well for carrying out the following tasks:
- Restoring databases, tables, and other data-related objects that may have been erased unintentionally or on purpose.
- Making copies of and backing up the data from earlier key points.
- Examining the use and manipulation of data over predetermined time frames.
Fail-safe
In the event of a system malfunction or other unanticipated occurrence, a fail-safe assures that previous data is protected (e.g., from a security breach).
Snowflake’s fail-safe feature enables it to retrieve past data for a (non-customizable) 7-day span. The time-travel retention period ends, and this period starts at that point. It is not a feature that can be turned on or off by the user, or tested independently. Because it is constantly on, Snowflake can use it to assist in data recovery. The amount of data Fail Safe stores is displayed in the Account view of the GUI’s Fail Safe storage usage.
Contact Us
RELATED BLOGS



