



























Are You Ready for AI Models Impact on Retail Sales?
11 March 2020
Confidence Intervals
4 April 2020
Published by
BluePi
Data-Driven Business Transformation
Product Recommendations Using HRNN
Both of these algorithms are collaborative in nature since interaction data between user and item are used for making recommendations.
Off the two, HRNN is quite new and not much information is available about it even on the AWS website. It was a struggle for us as well to understand how this amazing sounding algorithm worked. We did some research and found relevant information about it and now we are here with this blog following the spirit of sharing. And, therefore, we will be mainly talking about the session-based setting of recommendations and about HRNN and its working in this blog.
- HRNN stands for Hierarchical recurrent neural network which is mainly used for session-based recommendations.
- SIMS is based on neighborhood methods that compute the item-to-item similarity matrix from the historical interaction data for making recommendations.
Figure 1 shows the architecture of HRNN
Both of these algorithms are collaborative in nature since interaction data between user and item are used for making recommendations.
Off the two, HRNN is quite new and not much information is available about it even on the AWS website. It was a struggle for us as well to understand how this amazing sounding algorithm worked. We did some research and found relevant information about it and now we are here with this blog following the spirit of sharing. And, therefore, we will be mainly talking about the session-based setting of recommendations and about HRNN and its working in this blog.
A brief history of recommendation methods
A good amount of data is required for making quality recommendations. Classical approaches like matrix factorization and neighborhood methods both work well in this scenario when interaction is available. Matrix factorization is based on singular value decomposition(SVD), it basically constructs a user-item rating matrix for all combinations of users and items. The neighborhood method is based on item-to-item similarity, it constructs an item-to-item similarity matrix from the available interaction data between user and item. We will not be going into too much detail about the workings of these algorithms.
In the next section, we will see the shortcomings of both of these approaches and how HRNN came into the picture as well as its working.
What is the session-based setting for recommendations and why is it used?
Matrix factorization
In the case when users are anonymous and their profiling is not possible, classical recommendation approaches like matrix factorization are not recommended. The user might have not logged-in or there may be other privacy concerns. In this case which data can be used to recommend a product to the current user? Note that we don’t know anything about this user, no user identifier is available, therefore past transactional and click data is of no use here. This is where the session-based setting for recommendation comes into the picture. We can use the click information currently being captured at the website for making the recommendation in real-time. But this data is not suitable for the matrix factorization approach. What can be in this situation?
Neighborhood method
A natural solution to this problem was the item-to-item similarity recommendation approach(SIMS algorithm in AWS environment). This method is based on the concept that items that are clicked or purchased together are similar to each other. We can use the last click information and get similar items to the item from the precomputed item similarity matrix. But this approach considers only the last item that was clicked or purchased by the user to make a recommendation and useful information about previous clicks and purchases is not used. Also, all the users will be recommended the same items with this approach and we lose user-personalization in this scenario.
RNN
This is where session-based recommendation comes into the picture, Recurrent Neural Networks (RNN) is used to model the user behavior and preference within the current session. The current session will have data about the clicks and purchases made by the user. Let’s consider only using click data for now. Each click is given as an input to the RNN model and a score for every item in the catalog indicating the likelihood of being the next item in the session is given as output. During training, scores are compared to the next item ID in the session to compute the loss. RNNs have been recently used for the purpose of session-based recommendations outperforming item-based methods by 15% to 30% in terms of ranking metrics.
One issue with the RNN approach is that it only considers the current session to train the model, to learn about user preferences and make recommendations. But there are cases where a user might be logged-in or some form of user identifier might be present. In these cases, it is reasonable to assume that the user behavior in past sessions might provide valuable information for providing recommendations in the next session. This is where Hierarchical recurrent neural networks(HRNN) comes into the picture.
HRNN
HRNN model introduces an additional Gated recurrent unit(GRU) layer to model information across user sessions and to track the evolution of user interests over time. There are two GRU layers in HRNN in contrast to one layer in RNN, one is session-level which is similar to the RNN’s GRU layer and the other is user-level GRU. The session-level GRU models the user activity within sessions and generates recommendations. The user-level GRU models the evolution of the user across sessions and provides personalization capabilities to the session-level GRU by initializing its hidden state. In this way, the information relative to the preferences expressed by the user in the previous sessions is transferred to the session-level GRU.
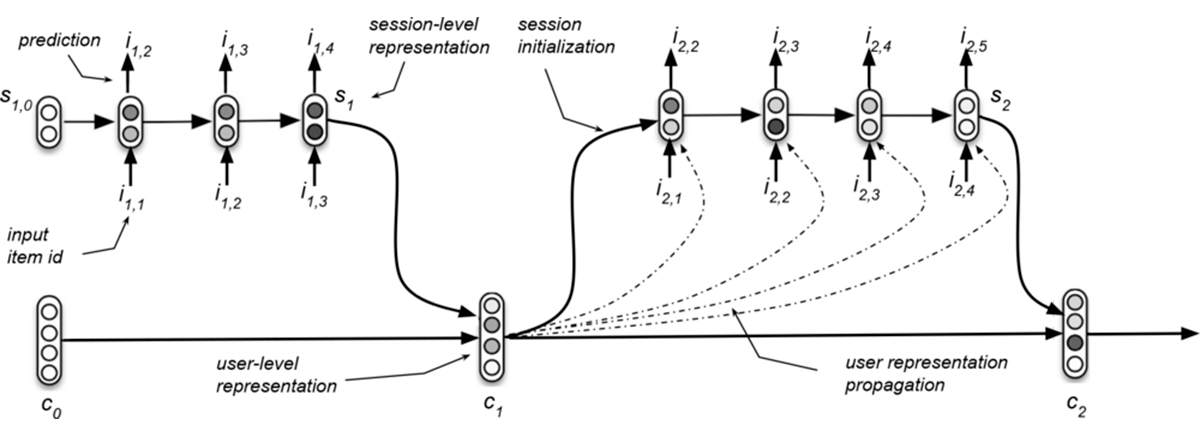
Figure 1: Graphical representation of the Hierarchical RNN model [1].
Note that the user-level GRU does not simply pass on the hidden state of the previous user session to the next but also learns (during training) how user sessions evolve during the time. In effect, user-level GRU computes and evolves a user profile that is based on the previous user sessions, thus in effect personalizing the session-level GRU
How does the HRNN model get trained?
- Sessions are grouped by user, i.e. different sessions are maintained for each user.
- Within each group, session events(purchase history) are sorted by time-stamp.
- Users are ordered at random for the training of the HRNN model.
- At the first iteration of the training:
- The first item of the first session of first N users constitutes the i/p to the HRNN.
- The 2nd item in each session constitutes its output.
- This output is then used as input for the next iteration of training and so on.
- In essence, how the model learns to make relevant recommendations can be understood by the following example. Talking in machine learning terms, if the user had purchased 3 items namely i1, i2, and i3 in this order only. Then in the first iteration of training, user id(user-vector) and i1 will be used as input to the model and i2 will be used as the output. The model will generate recommendations by generating scores for each item and i2 will be used to compute loss and adjust the weight of the model, since i2 was the true event that had happened, if the model had made recommendations of some other item instead of i2 than model weights will be adjusted so as to make it learn to recommend i2 instead of some other item. The model actually gives score for each item in the catalog telling the likelihood for it to the next item in the session, and TOP1 is choice of loss function. But the above example was only for understanding purpose.
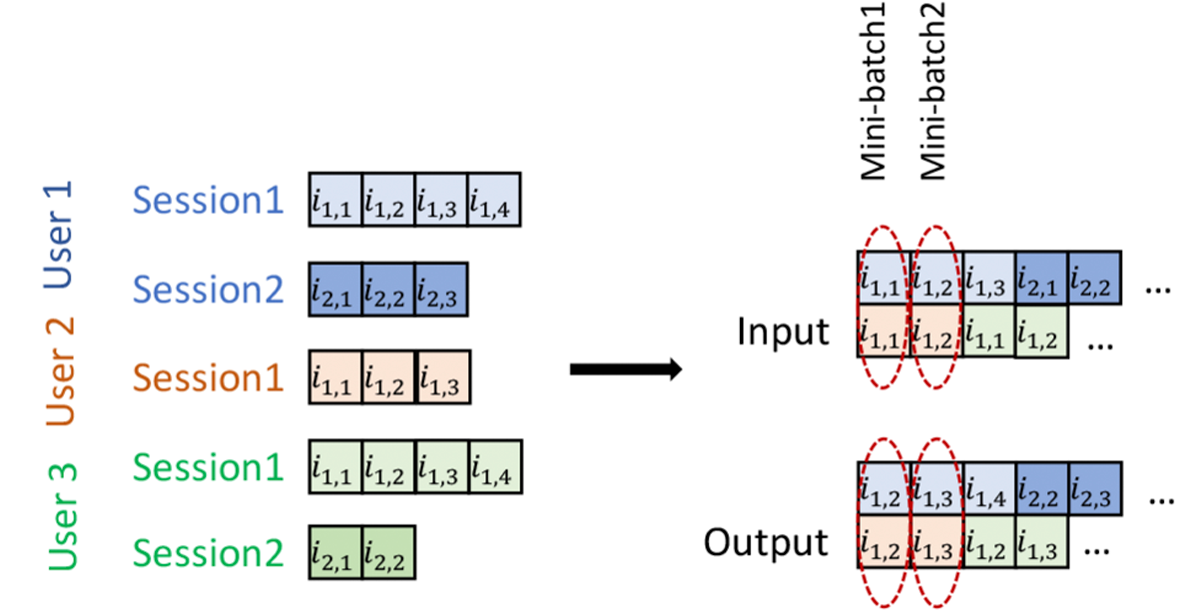
Figure 2: Input and output data used to train the HRNN model [1]
Can HRNN be used when we have only sales data and we are not in the true session-based setting and we only have transaction data to work with?
Yes
Reason: Whole of the transaction history of the user will be considered as a session for the user. The model will be trained using this data only and will make recommendations accordingly.
We skipped into going into detail of how the weights were adjusted and about the loss function used in this blog. Hopefully, they will be covered in the next blog.
References
- https://arxiv.org/pdf/1706.04148.pdf
- https://arxiv.org/pdf/1511.06939.pdf







{kind=link}
{kind=link}